Seamless JSON config files integration with EasyJsonCpp
As a Backend Engineer, ensuring confidentiality and security is paramount in my work, especially when handling sensitive data like API key and private configuration elements that require strict confidentiality.
While I strive to contribute to the open-source community, I am mindful of safeguarding my own privacy and security by avoiding any inadvertent disclosure of sensitive information. Consequently, I have adopted a simple technique which consists of loading configuration data from a JSON config file into a map or multiple maps (Or any data structure of choice) to enable seamless and efficient data retrieval only when and where needed.
This document presents an illustration of a C++ class, SomeClass, and utilizes its methods to demonstrate the core concepts of how to keep sensitive data like API keys secure and private.
1
2
3
4
5
6
7
8
9
10
11
12
EasyJsonCPP/
│
├── include/
│ ├── easyJson/
│ │ ├── easyJsonCPP.hpp
│ │ └── header.hpp
│ └── mathlib.hpp
│
├── src/
│ └── MathFunctions.cpp
│
└── CMakeLists.txt (or another build script)
Table of content
Configuration File Structure
I follow a naming convention for my config files, which involves naming them as PROJECT_config.json where “PROJECT” represents the project name. These config files follow a JSON array of objects structure where each element or section holds specific data for various components.
This format allows compact organization and easy data retrieval, with simple Json object iteration. Which simplify the process of extracting required information for each component.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
[
{
"info": "some string",
"Item1": [
{
"api": "data",
"port": "80"
}
]
},
{
"Item2": [
{
"endpoint": "to the moon",
"token": "token"
}
]
},
{
"Item3": [
{
"client_secret": "ipsum lorem",
"client_key": "sed do eiusmod tempor"
}
]
}
]
In particular, all of my project config files include an "info" section where I store essential project details. This section contains information such as:
- run level mode (debug, off, warn, info, error, critical)
- version
- filename
- author
- description.
- etc …
1
2
3
4
5
6
7
8
9
10
11
12
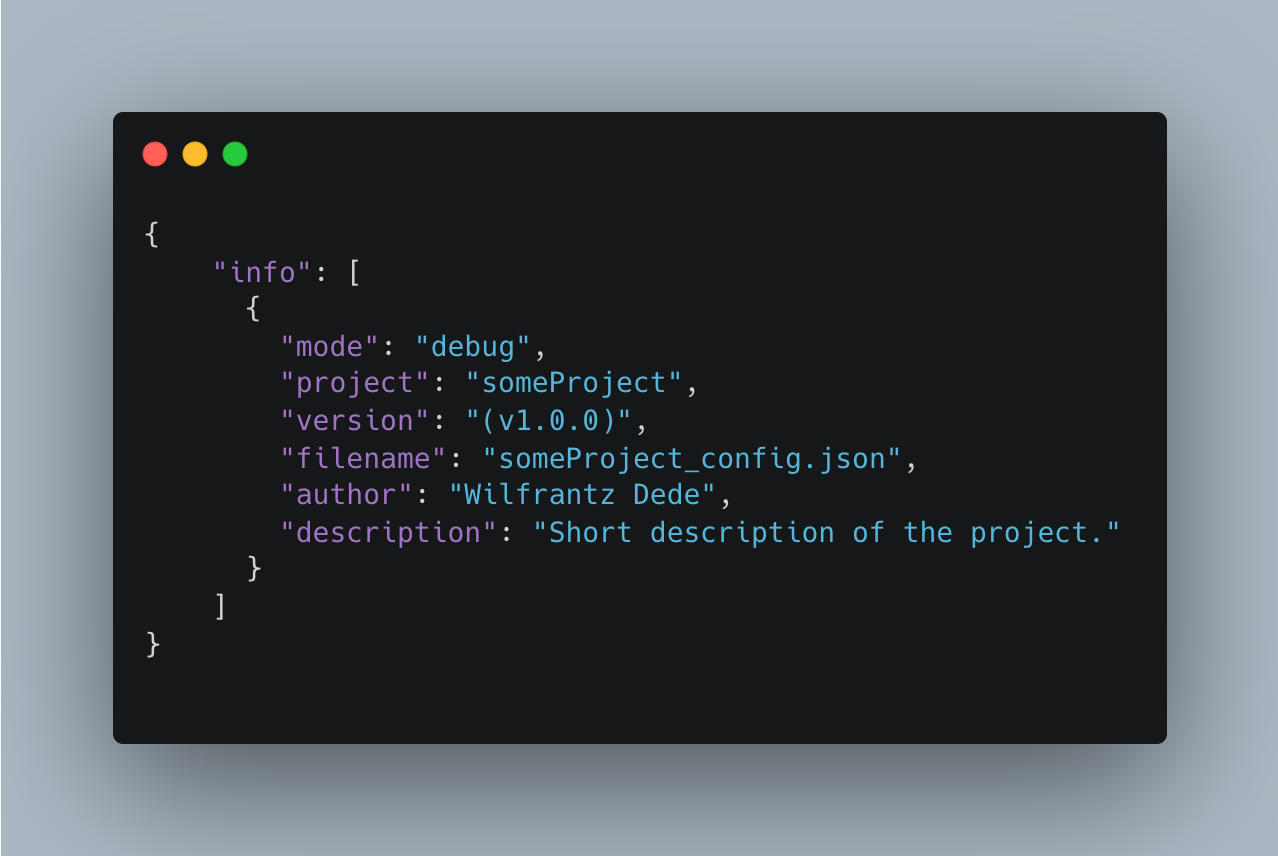
{
"info": [
{
"mode": "debug",
"project": "someProject",
"version": "(v1.0.0)",
"filename": "someProject_config.json",
"author": "Wilfrantz Dede",
"description": "Short project description."
}
]
}
Additional sections can be added as needed, depending on the specific needs of the project. For instance, if the project involves retrieving data from the Twitter API, a dedicated "twitter" section can be created within the config file.
This section would contain all the necessary properties and configurations related to interacting with the Twitter API.
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"twitter": [
{
"api_key": "SECRET_API_KEY",
"media_endpoint": "https://api.twitter.com/2/media/",
"api_url": "https://api.twitter.com/1.1/statuses/show.json?id=",
"api_secret": "API_SECRET",
"access_token": "ACCESS_TOKEN",
"access_token_secret": "ACCESS_TOKEN_SECRET",
"bearer_token": "BEARER_TOKEN"
}
]
}
By structuring the config file in this manner, it becomes flexible and adaptable to accommodate different project requirements and integrate with various external services or APIs.
Load Configuration Data Efficiently
The configuration data is structured as a JSON array of objects within the JSON file. This approach offers enhanced flexibility, as new components can be added without requiring any modifications to the program itself.
The config file becomes a scalable solution, enabling easy expansion and incorporation of additional components as needed. This design choice promotes agility and simplifies the process of adapting the program to evolving requirements without disrupting its core functionality.
The loadConfig() method serves the purpose of fetching the configuration data from the designated configuration file. It initiates by performing preliminary checks to determine whether the _configFile variable is empty. In which case, the program logs an error message and terminates promptly.
The method then parses the JSON content of the file, ensuring it is in the form of a JSON array of objects as emntioned in the configuration file structure section.
It iterates over each object within the array, validating their format and follow these important steps:
Iterates over the key-value pairs
For each object, loadConfig() further iterates over the key-value pairs within, processing them based on their value type.
1
2
3
4
5
6
7
8
9
10
11
12
for (const auto &object : root)
{
if (!object.isObject())
{
throw std::runtime_error("Invalid format for object in configuration file.");
}
// iterates over the key-value pairs within
for (auto const &key : object.getMemberNames())
{
// process key by value type.
}
}
Process value by type
loadConfig() processes string and array values (specifically, an array of objects with string key-value pairs).
- If the value is an array
The code processes the data from the arrays and adds it to the corresponding config map. For example, in a Twitter class, a _configMap map stores Twitter API data, and in a TikTok class, another _configMap map stores TikTok API data. This improves efficiency and allows easy access to the necessary API information for each class.
Further, using a vector containing a list of target keys allows seamless iteration and efficient loading of the corresponding map.
1
const std::vector<std::string> _targetKeys = {"twitter", "tiktok", "instagram", "facebook"};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
for (const auto &key : object.getMemberNames())
{
const auto &value = object[key];
// Check if the key matches any target key in the vector
if (std::find(targetKeys.begin(), targetKeys.end(), key) != targetKeys.end())
{
processTargetKeys(value, key);
}
else
{
// Process string and integer.
}
}
The ProcessTargetKeys() method takes a configValue and a key as parameters. It processes the configuration values based on the specified target keys. It iterates through each element and further iterates through the key-value pairs.
The method handles specific target keys allowing efficient loading of data into the respective config map. If the value type is invalid, an exception is thrown. This method further enhances the flexibility and scalability of the code for handling different target keys and ensures proper configuration data management.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
void SomeClass::ProcessTargetKeys(const Json::Value &configValue, const std::string &key)
{
if (configValue.isArray())
{
for (const auto &element : configValue)
{
for (const auto &subKey : element.getMemberNames())
{
const auto &subValue = element[subKey];
if (subValue.isString())
{
tiktok::TikTok tikTok;
twitter::Twitter twttr;
instagram::Instagram instgrm;
// Add data to the corresponding config map based on the key
switch (hashString(key.c_str()))
{
case hashString("Twitter"):
{
loadConfigMap(subKey, subValue.asString(), twttr.mapGetter());
break;
}
case hashString("TikTok"):
{
loadConfigMap(subKey, subValue.asString(), tikTok.mapGetter());
break;
}
case hashString("Instagram"):
{
loadConfigMap(subKey, subValue.asString(), instgrm.mapGetter());
break;
}
/// NOTE: Add more cases for other target keys as needed
default:
{
// Invalid key
throw std::runtime_error("Invalid key name in the configuration file.");
}
}
}
else
{
// Invalid value type
spdlog::error("Invalid format for object: {} in the configuration file.", subValue.asString());
throw std::runtime_error("Invalid format for object in the configuration file.");
}
}
}
}
// Add more conditions for other target keys as needed
else
{
// Invalid value type
throw std::runtime_error("Invalid format for object value in the configuration file.");
}
}
If the value is a string
It converts numeric values to string and adds the key-value pair to a main _config map in a base class or main routine. Any invalid value types encountered result in appropriate error handling and exceptions being thrown.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
if (value.isString())
{
// Add data to main _config map.
_config[key] = value.asString();
}
else if (value.isInt())
{
// convert to string, add data to main _config map.
_config[key] = std::to_string(value.asInt());
}
else
{
// Invalid value type
throw std::runtime_error("Invalid format for object value in configuration file.");
}
Here’s an example of a simple hashString function that utilizes std::hash from the <functional> header that can be used for string comparison:
1
2
3
4
constexpr std::size_t hashString(const char* str)
{
return std::hash<const char*>{}(str);
}
remember to add
#include <functional>to your header file.
Please note that this is a simple hash function for demonstration purposes. In a production environment, you may want to consider using a more robust hashing algorithm.
In case of any exceptions during the process, the method logs an error message indicating the issue encountered while reading the configuration file. At this point, the method can either return an error code or throw an exception, depending on the prefered error handling strategy.
Retrieve data from a map
The getFromConfigMap method provides a convenient way to read values from a map. It takes a key parameter indicating the desired configuration key to retrieve. The function returns the corresponding value from the config map or an error string if the key is not found.
Internally, the function attempts to retrieve the value using the std::unordered_map::at function, which throws a std::out_of_range exception if the key is not present in the map. In the catch block, an error message is logged, and an error string is constructed using the provided key. This error string is then returned.
The function utilizes a static error string to ensure the error message remains accessible even after the function’s scope ends. This prevents the caller from dealing with dangling references.
It enhances code readability and maintainability by encapsulating the logic for accessing a config map and handling missing key scenarios in a single function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/// @brief Read from the config file
/// @param key[in] The key to read from the config file.
/// @return The value of the key or an error string.
const std::string &SomeCLass::getFromConfigMap(const std::string &key)
{
static std::string errorString;
try
{
return _config.at(key);
}
catch (const std::out_of_range &)
{
_logger->error("Error retrieving key: {} from config file.", key);
static const std::string errorString = "Error retrieving " + key + " from config file";
return errorString;
exit(1);
}
return errorString;
}
Conclusion
These practices leverage object-oriented programming (OOP) features like encapsulation, confidentiality and security. The encapsulation principle ensures that sensitive information, such as API keys and private configuration elements, is encapsulated within the appropriate classes, preventing direct access and inadvertent exposure.
Additionally, these techniques enhance the overall robustness and maintainability of the codebase. By encapsulating the configuration loading and retrieval logic within dedicated functions and classes, the codebase becomes more modular and organized. This improves code readability and makes it easier to maintain and update in the future.
Furthermore, the use of classes, along with proper data encapsulation and abstraction, allows for a clearer separation of concerns and promotes code reuse. This enhances the overall efficiency of configuration data loading and retrieval, enabling seamless integration with external services and APIs.
Overall, by leveraging OOP principles like encapsulation, the codebase becomes more secure, robust, and maintainable, providing a solid foundation for handling sensitive information and ensuring the smooth functioning of the system.